🗃 ArchiveBox
Personal self-hosted web archiving is easy with ArchiveBox. Save pages you see on the internet for later and build your own personal internet archive.

Ever wanted to have your own personal internet archive? ArchiveBox (code) is a F/OSS for just that – web archiving.
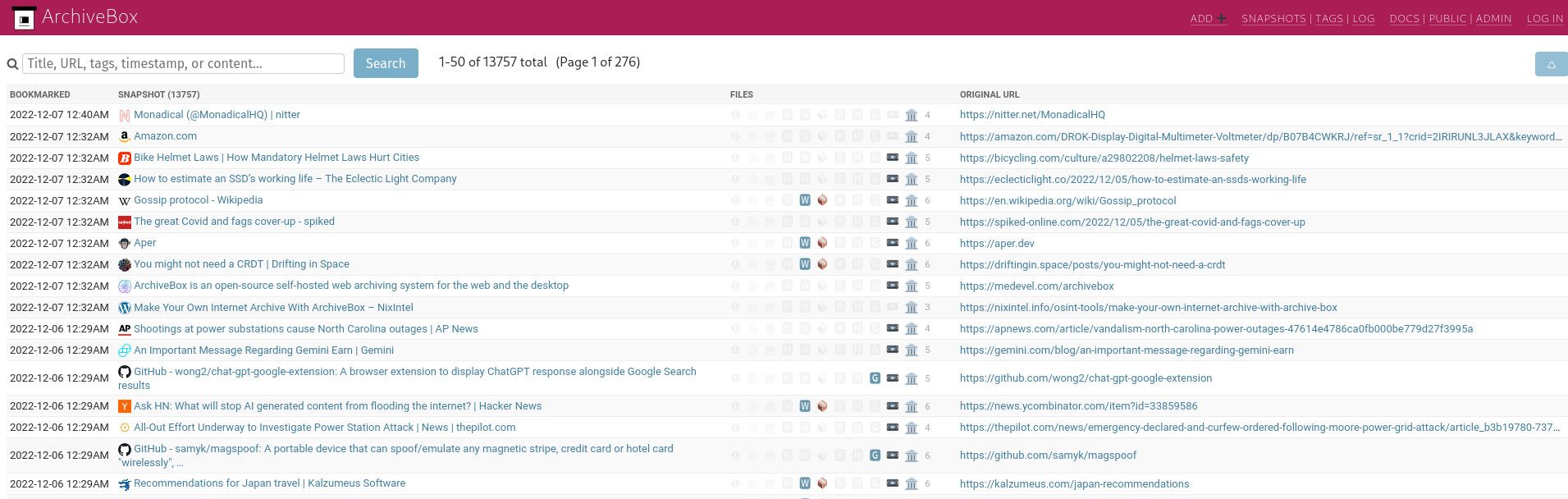
Save pages that you want to keep for later, and makes sure that they're always visible to you – saving media/PDFs/images and ArchiveBox does a little bit of crawling to make sure the page is represented truthfully when you view it later.
ArchiveBox offers multiple methods of archiving:
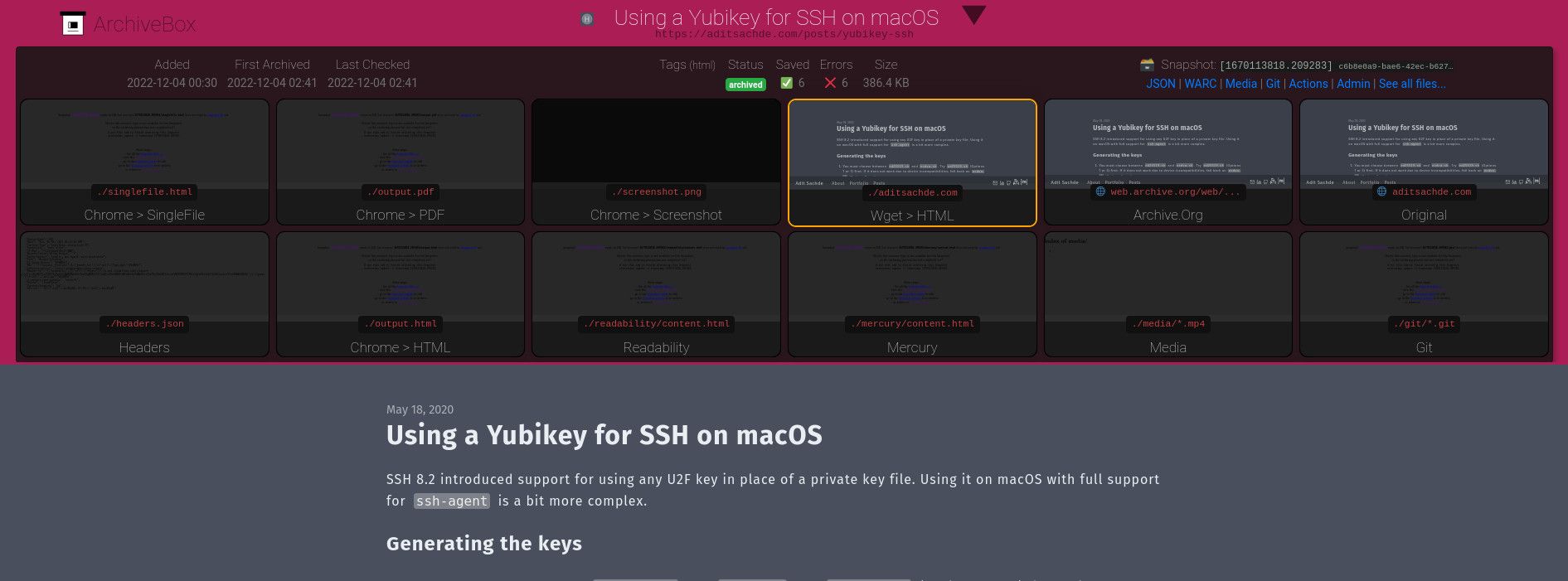
So even if you can't necessarily run the archiving yourself, you can always make a secondary backup of a source like Archive.org.
Running ArchiveBox
ArchiveBox has fantastic, clear and easy to read documentation (and a great README), so regardless of how you want to run it, check those resources first.
ArchiveBox is docker friendly, with an official image, so it's easy to run locally as a server with the admin interface running at localhost:8000:
docker run
-v $PWD/archive-box-data:/data
-p 8000:8000
archivebox/archiveboxNote that you can also use archivebox as just a command (with docker), so you don't have to necessarily install it and run it as a server:
docker run -v $PWD:/data -it [archivebox subcommand] [--args]This makes it easy to integrate archivebox into other automation/cron tasks, etc.